Archiving Flash: Best Practice
Flash, like various web technologies before it, was a popular way to build websites, games, and other types of interactive content online. Flash slowly fell out of favor and was ultimately deprecated. The Chrome web browser is scheduled to remove support for Flash websites on December 31st, 2020.
an important note
As long as a Flash site remains online it will still be accessible and able to be archived using the strategies outlined below, even after the deadline.
Capturing Flash sites that are still online
Conifer created remote browsers, a system of browsers running in an emulated environment, precisely for use cases like preserving Flash. Pre-configured browsers that have Flash and other deprecated web technologies enabled can be used to capture and provide replay for Flash works in a stable, future-tolerant way.
Different from classic HTML web pages with their links, images, and other resources clearly described, Flash does not expose any semantic information about what areas of the screen are interactive or how resources are loaded. This makes it hard for classic web archiving crawlers to handle Flash, but makes Flash a good candidate for the user-driven web capturing Conifer offers.
For the best results when using Conifer to capture Flash, interact with all aspects of the work you wish to capture, as you would with a regular webpage. One Flash piece with embedded sound may load all of its external media as the page loads. A different Flash piece might load the audio on demand, only downloading external media just before it plays. You can get a sense of how a Flash piece loads data by watching the size counter during capture.
Additionally, some Flash works might incorporate more than one Flash file, staging each .swf on a separate web page. For this reason, it may be required to navigate fully through the piece in order to capture all of the interactive elements of a Flash piece.
Uploading an offline website
If a website has gone offline, it cannot be captured with Conifer. However, if you still have a copy of the files representing the old website on your local disk, you can package them into a WARC file and upload them to Conifer. You will then be able to organize and share the old website like any other Conifer collection.
⚠️ Please note that this only works with sites termed “static sites,” websites made of file types such as HTML, CSS, client-side JavaScript, images, videos, and so forth. Sites utilizing one or more databases or server-side scripting (for instance, via Python, node, PHP, CGI, or ASP) are not supported.
Installing warcit
warcit is a command-line tool to convert locally saved directories of web data (such as HTML, CSS, and Flash files) into WARC files. The WARC format, or Web ARChive format, is a standard web archiving format. After bundling your website’s static files with warcit, the resulting WARC file can be uploaded to Conifer for further access and curation. warcit is written in Python and is operated via the terminal.
Windows
To use warcit on Windows, install Python by downloading the latest stable version listed on the Python Releases for Windows page and launch the installer. Select “Add Python 3.x to PATH” in the installer to make sure that Python programs can be run from the terminal. (Users with workflows requiring multiple concurrent Python installations may wish to skip this checkbox and consult the documentation for suggestions.)
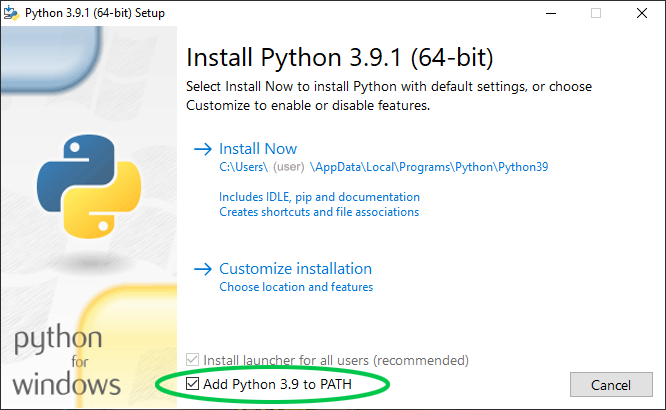
This will install both Python itself and the package manager pip. Launch the Command Prompt and type py --version. If everything is installed correctly, Python will print its version number. Next, type pip install warcit to install warcit.
Mac
For recent versions of OSX, python3 is the preferred python version to work with. To install warcit, first install the pip3 package manager if you don’t already have it installed:
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.py
Once that is complete, you can then proceed to install the warcit package:
pip3 install warcit
Linux
Most Linux distributions already come with Python pre-installed. On Ubuntu, you might have to install the package manager pip by typing sudo apt install python3-pip. You can then install warcit by typing sudo pip3 install warcit.
Once warcit is installed, you can type warcit --version in the terminal, and warcit will print its version number.
Using warcit
When website resources are saved to a typical file system on a computer disk or in a ZIP archive, they are addressed via their local file path (for example, C:\Users\MyName\my_site_files\home.swf). Web resources, by contrast, are addressed via a global URL. warcit can convert a local directory or ZIP file into a web archive, but it must be provided with a base URL with which to regenerate URLs. For this reason, warcit requires at least two parameters: a base URL and the name of a directory containing website resources.
warcit http://oldsite.org/ oldsite
In the terminal, the command name (“warcit”) and each parameter (URL prefix, name of directory) have to be separated by spaces.
Type warcit http://oldsite.org/ into the terminal. Include the trailing slash in the URL, and tap space after the URL so that the terminal can distinguish between URL and directory name. Then, carefully copy and paste the full path name of the directory you want to convert to WARC into the terminal window (or drag and drop the directory directly into the terminal to populate it with the exact directory name). After you hit enter, a WARC file with the same name as the directory will be generated.
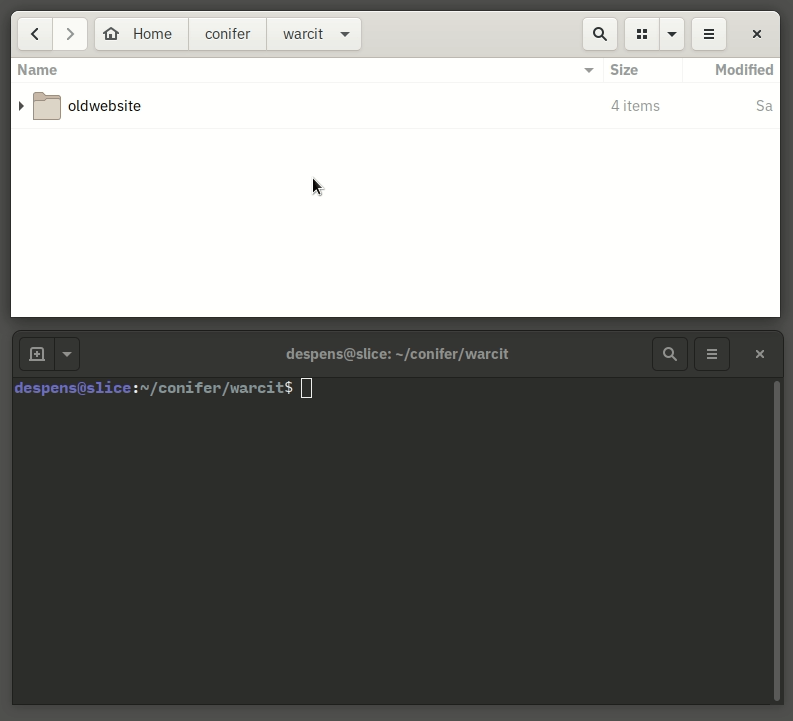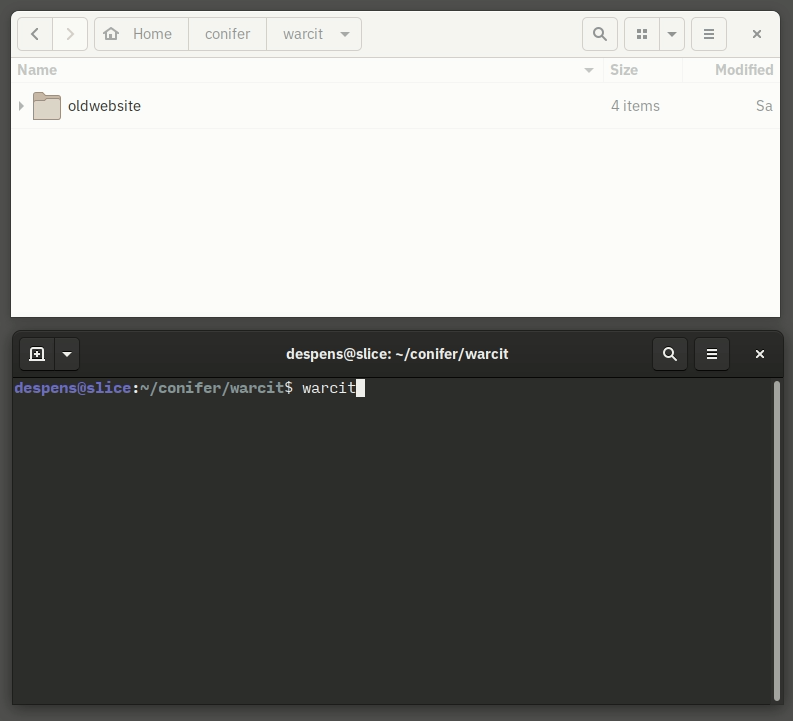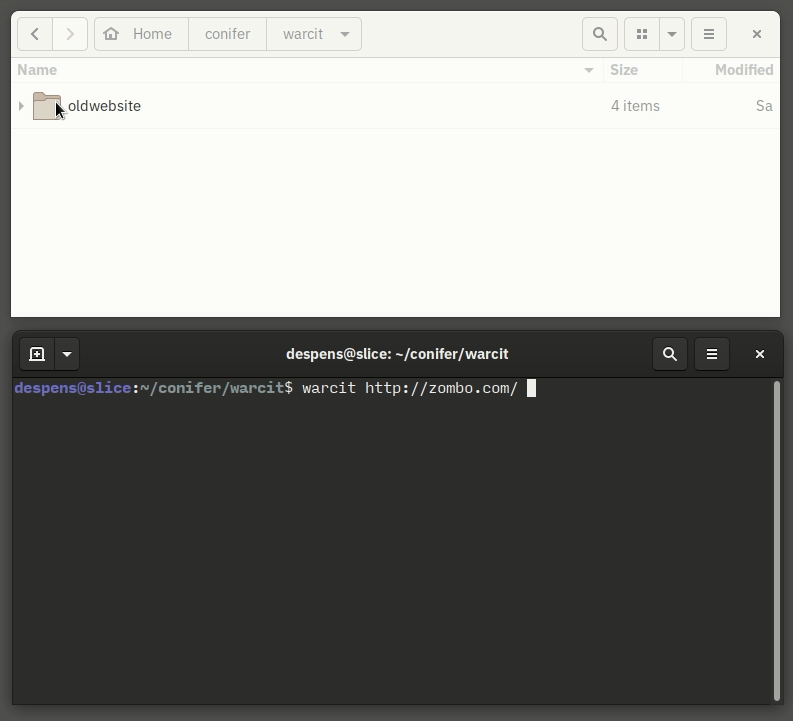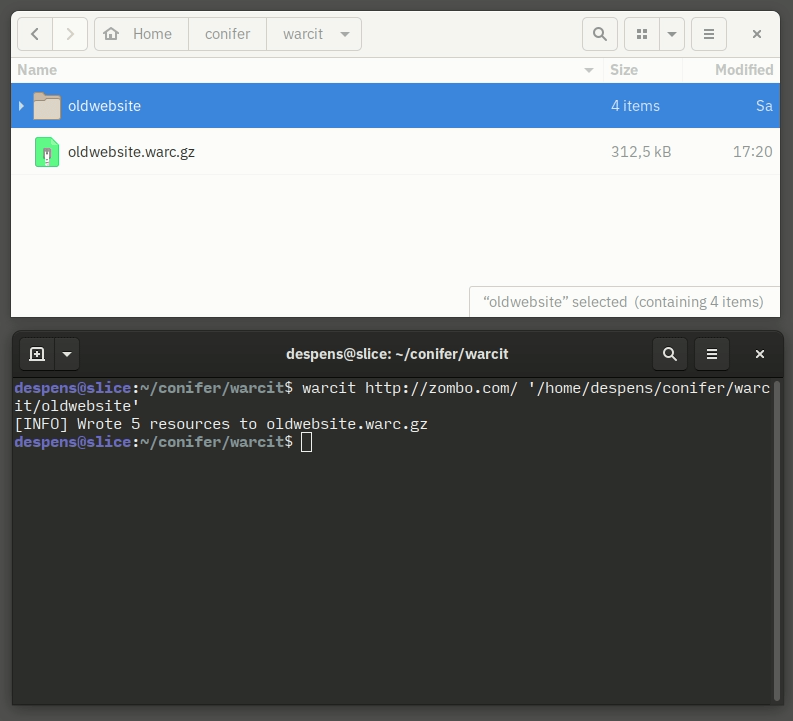
The WARC file will be located in your current working directory (this is likely your home directory, unless you navigated to a specific directory in the terminal—for instance, by using the cd command). Find the WARC file using your operating system’s file explorer (Windows Explorer, Apple Finder, Gnome Files, etc) and upload it to Conifer.
Advanced warcit
WARC files hold not only information about a file’s URL, but also information about the date the file was captured. By default, warcit will populate this data by using the date when files were last modified on the local disk. However, this information is in many cases wrong, and may show the date the files were copied or downloaded. Using the -d parameter allows the user to set a custom date using the YYYYMMDDhhmmss format (Year, Month, Day, hour, minute, second):
warcit -d 20031210145807 http://oldsite.com/ oldwebsite
This will set the web archive date to 10 December 2003, 2:58:07pm. All times are interpreted as located in the UTC time zone.
To learn about more warcit features, type warcit --help in the terminal and visit the warcit GitHub page.